Thông thường, khi dữ liệu đã được “nấu chín” vào một mô hình AI thì việc lấy nó ra lại là điều không tưởng – chẳng khác gì cố tách trứng khỏi một chiếc bánh đã nướng xong.
FLEXOLMO LÀ GÌ
FlexOlmo là một mô hình ngôn ngữ AI mã nguồn mở, cho phép nhiều bên cùng huấn luyện mà không cần chia sẻ dữ liệu gốc, và đặc biệt có thể rút lại hoặc kiểm soát dữ liệu đã đóng góp bất cứ lúc nào.
MÔ HÌNH AI CHO PHÉP “RÚT LẠI” DỮ LIỆU ĐÀO TẠO
Thế nhưng, Viện AI Allen (Ai2) vừa ra mắt một mô hình mới mang tên FlexOlmo cho phép điều khiển và thậm chí rút lại dữ liệu huấn luyện khỏi mô hình ngay cả sau khi mô hình đã được xây dựng. Đây là một cách tiếp cận đột phá thách thức lối mòn hiện nay khi các hãng AI lớn “nuốt” dữ liệu khắp nơi và khóa chặt chúng trong các mô hình kín như bưng. FlexOlmo mở ra viễn cảnh người cung cấp dữ liệu vẫn nắm quyền đối với dữ liệu của mình kể cả sau khi đã đóng góp vào quá trình huấn luyện AI – nghe hấp dẫn đấy chứ?
- Xem thêm tại: https://allenai.org/blog/flexolmo
DỮ LIỆU LÀ “NHIÊN LIỆU” NHƯNG CHỦ DỮ LIỆU ĐANG THIỆT THÒI
Trong lĩnh vực AI, dữ liệu được ví như nhiên liệu phản lực cho các mô hình ngôn ngữ lớn. Mô hình mạnh cỡ nào phần lớn phụ thuộc vào dữ liệu huấn luyện nhiều hay ít, đa dạng hay không. Tuy nhiên, việc xây dựng tập dữ liệu mở đang là nút thắt cổ chai lớn: rất nhiều tổ chức, cá nhân sở hữu dữ liệu giá trị nhưng ngại chia sẻ vì đủ thứ rủi ro và hạn chế. Hãy nghĩ mà xem, quy trình AI truyền thống có quá nhiều bất cập: thiếu linh hoạt (dữ liệu đã đưa vào một lần là coi như “dính chặt”, không thể chủ động thêm bớt hay rút ra), và chủ dữ liệu cũng mất kiểm soát (một khi dữ liệu đã công bố thì không thể biết ai dùng hay giới hạn được mục đích sử dụng). Chưa hết, họ còn đánh mất giá trị độc quyền của “tài sản dữ liệu” quý giá sau khi nó bị chia sẻ tràn lan, và thường chẳng được ghi nhận công lao gì khi đóng góp dữ liệu vào việc huấn luyện mô hình. Kết cục là nhiều bên có dữ liệu muốn góp cũng đành chùn bước.
Hệ quả dễ thấy: các mô hình ngôn ngữ hiện nay hoặc là dùng dữ liệu công khai (web, sách báo) với chất lượng không đồng đều, hoặc là dữ liệu nội bộ “cây nhà lá vườn” dẫn đến thiên lệch. Nhiều lĩnh vực quan trọng như y tế, tài chính, chính phủ sở hữu dữ liệu rất giá trị nhưng phải “đắp chiếu” vì không thể chia sẻ ra ngoài do lo ngại pháp lý và bảo mật. Rõ ràng cần một cách tiếp cận mới để những kho dữ liệu quý này có thể được tận dụng vào phát triển AI mà chủ dữ liệu vẫn yên tâm. Và đó chính là lý do FlexOlmo xuất hiện.
FLEXOLMO – KHI CHỦ DỮ LIỆU THẬT SỰ CẦM LÁI MÔ HÌNH AI
FlexOlmo được Ai2 giới thiệu như một mô hình ngôn ngữ mở thế hệ mới, cho phép hợp tác huấn luyện AI theo cách linh hoạt chưa từng có. Với FlexOlmo, người sở hữu dữ liệu có thể góp sức huấn luyện mô hình mà không phải đánh đổi quyền kiểm soát dữ liệu của mình. Nói một cách đơn giản, bạn có thể đóng góp tri thức từ dữ liệu của mình vào mô hình chung nhưng không cần giao nộp dữ liệu thô. Thay vì gửi cả đống data cho ai đó huấn luyện hộ, bạn sẽ tự huấn luyện một mô hình con trên dữ liệu của mình rồi đóng góp bản sao đã được “học” đó vào mô hình AI tổng hợp chung. Dữ liệu gốc chưa hề rời khỏi tay bạn, và bạn cũng quyết định được khi nào kiến thức từ dữ liệu của mình được kích hoạt sử dụng hoặc khi nào thì tắt đi. Hay hơn nữa, bạn còn được ghi nhận mỗi khi phần dữ liệu bạn đóng góp được dùng đến trong quá trình mô hình đưa ra kết quả – nghe như “AI cộng đồng có credit” vậy!
Quan trọng là, mọi thao tác đóng góp và rút lui đều do bạn chủ động. FlexOlmo thiết kế để mỗi bên dữ liệu có thể tham gia huấn luyện một cách độc lập, không đồng bộ với nhau. Bạn muốn tham gia lúc nào tùy ý, và nếu cần dừng hoặc rút dữ liệu ra thì cũng không ảnh hưởng đến hệ thống chung. Không cần tất cả “chung khẩu hiệu” rồi cùng train một lượt như kiểu federated learning cổ điển – FlexOlmo cho phép mỗi người “một vườn một nhà”, xong xuôi đâu đó thì góp phần đã huấn luyện vào mô hình chung. Chẳng hạn, một nhà xuất bản có thể tham gia đóng góp dữ liệu văn bản từ kho bài báo của họ vào mô hình, rồi sau đó gỡ bỏ phần mô hình đã huấn luyện trên dữ liệu đó ra khỏi mô hình tổng nếu có tranh chấp pháp lý hoặc công ty không muốn tiếp tục cho mô hình dùng nội dung của mình nữa. Mọi thứ linh hoạt đúng nghĩa: dữ liệu của bạn, bạn cầm lái quyết định hành trình của nó trong vòng đời AI.
KIẾN TRÚC “HỖN HỢP CHUYÊN GIA” ĐỘC ĐÁO CỦA FLEXOLMO
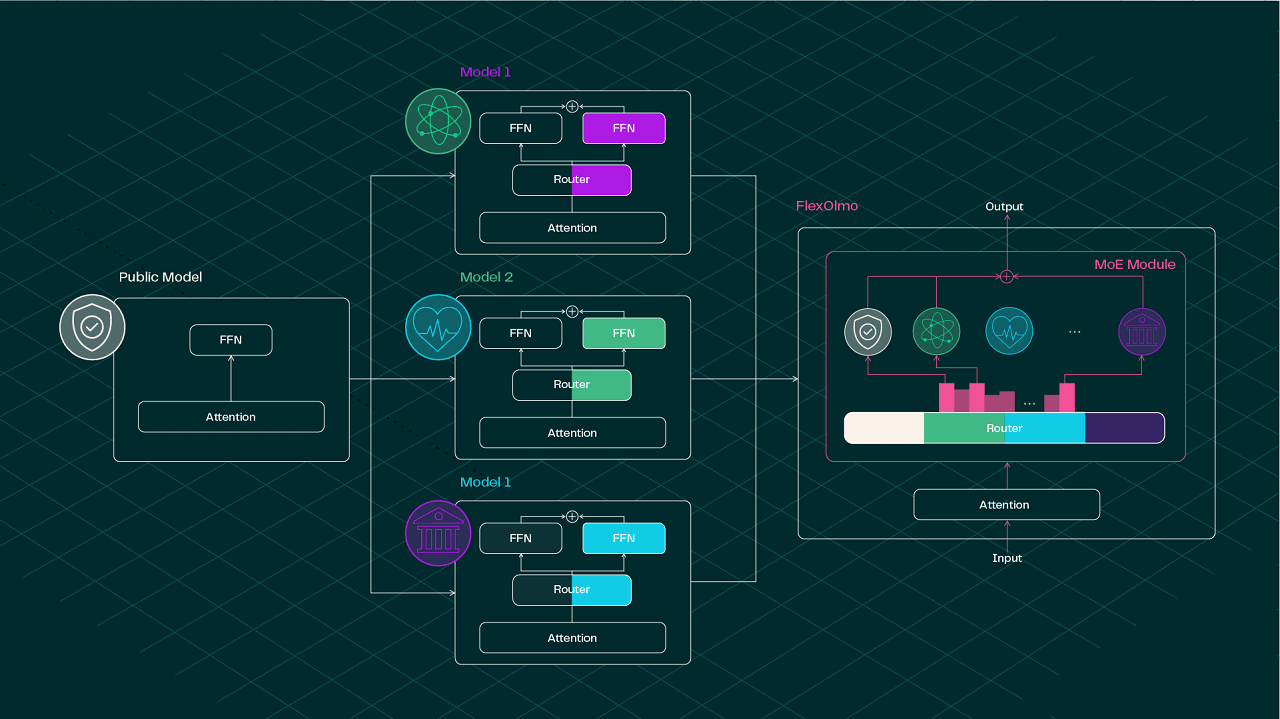
Làm thế nào FlexOlmo có thể “ghép” nhiều mô hình con độc lập mà vẫn hoạt động trơn tru như một mô hình duy nhất? Bí quyết nằm ở kiến trúc Mixture-of-Experts (MoE) – tạm hiểu là “hỗn hợp chuyên gia” trong đó nhiều mô hình nhỏ (chuyên gia) được kết hợp thành một mô hình lớn hơn. Mỗi expert sẽ đảm nhận một “mảng” dữ liệu khác nhau và được huấn luyện chuyên sâu trên dữ liệu đó. Điểm mấu chốt là nhóm Ai2 đã nghĩ ra cách hợp nhất các mô hình chuyên gia huấn luyện riêng rẽ sao cho khi ghép lại, chúng phối hợp nhịp nhàng như một đội banh nhiều siêu sao mà không giẫm chân nhau.
Cụ thể hơn, FlexOlmo bắt đầu từ một mô hình nền công khai (gọi là anchor model) làm gốc. Mỗi chủ dữ liệu sẽ nhân bản mô hình anchor này và dùng nó làm nền tảng “mỏ neo” để huấn luyện mô-đun chuyên gia của riêng mình. Trong quá trình đó, mô hình anchor được đóng băng (không cập nhật tham số) và đóng vai trò giữ cho expert của bạn học theo một khuôn khổ chung. Nhờ có cùng một “gốc rễ” anchor, các expert từ các bên khác nhau sau này ghép lại sẽ tương thích với nhau, tránh tình trạng “ông nói gà, bà nói vịt” do mỗi người tự xưng một kiểu. Sau khi từng expert huấn luyện xong, FlexOlmo sẽ tích hợp chúng vào một mô hình MoE hợp nhất, kèm theo một bộ định tuyến (router) để quyết định luồng dữ liệu đi vào expert nào khi suy luận (inference).
Đặc biệt, FlexOlmo không cần huấn luyện tất cả chuyên gia cùng lúc hay huấn luyện chung một router phức tạp. Thay vào đó, router của FlexOlmo được khởi tạo dựa trên các đặc trưng miền (domain-informed embeddings) rút ra từ chính mỗi tập dữ liệu, giúp định tuyến đầu vào đến đúng expert phù hợp mà không đòi hỏi phải “dạy” router biết hết mọi thứ ngay từ đầu. Nôm na thì mỗi expert được gắn một “tín hiệu nhận dạng” riêng tương ứng với lĩnh vực dữ liệu của nó, và router dựa vào đó để gán câu hỏi đầu vào cho expert nào “rành” nhất. Nhờ thiết kế này, các chủ dữ liệu có thể đóng góp module của mình bất cứ khi nào (train xong là ghép vào, không cần chờ ai) và cũng có thể linh hoạt bật/tắt expert đó khi chạy mô hình tùy tình huống. Đây chính là chìa khóa giúp FlexOlmo đạt được sự linh hoạt chưa từng có so với cách huấn luyện mô hình truyền thống hoặc thậm chí so với học liên kết federated learning trước đây. Hơn nữa, mặc dù cách làm của FlexOlmo có nét tương đồng với ý tưởng ghép mô hình (model merging) từng được nghiên cứu, nhưng FlexOlmo được thiết kế riêng để xử lý trường hợp các mô hình thành phần được train trên dữ liệu hoàn toàn rời rạc, khác biệt. Những kỹ thuật ghép mô hình trước đây thường “bó tay” khi dữ liệu các bên quá khác nhau, trong khi FlexOlmo lại xử lý ngon ơ bài toán này nhờ kiến trúc thông minh của mình.
HIỆU NĂNG THỰC TẾ: VỪA “ĐA NĂNG” VỪA “CHUYÊN MÔN”
Ý tưởng nghe hay, nhưng FlexOlmo có thật sự “bá đạo” khi triển khai không? Nhóm nghiên cứu tại Ai2 đã tiến hành loạt thử nghiệm để kiểm chứng. Họ xây dựng một tập dữ liệu tổng hợp gọi là “FlexMix” (bao gồm nhiều nguồn dữ liệu khác nhau như sách, website, v.v) và huấn luyện mô hình FlexOlmo với quy mô khoảng 37 tỷ tham số (tương đương 1/10 độ lớn của mô hình mở lớn nhất hiện nay của Meta).
Kết quả rất ấn tượng: mô hình FlexOlmo hợp nhất vượt trội hoàn toàn so với từng mô hình con (expert) đơn lẻ trên mọi nhiệm vụ đánh giá, và thậm chí điểm số trung bình còn cao hơn khoảng 10% so với hai phương pháp ghép mô hình độc lập khác cũng được đem ra so sánh trên các benchmark chuẩn. Nói cách khác, bằng việc thêm các “expert module” từ dữ liệu riêng, hiệu năng mô hình tăng lên đáng kể so với mô hình gốc chỉ xài dữ liệu công khai thông thường.
Thậm chí, FlexOlmo 33B này đạt chất lượng sát nút một mô hình tưởng tượng được huấn luyện trên toàn bộ dữ liệu gộp chung (cả công khai lẫn dữ liệu riêng) – tức là gần đạt “đỉnh” như thể không hề có sự phân chia dữ liệu ngay từ đầu vậy. Đáng chú ý hơn, mô hình hợp nhất không làm mai một kiến thức chuyên môn của từng expert, trái lại còn giữ vững hoặc tăng cường khả năng trả lời các câu hỏi chuyên ngành nhờ có đa dạng nguồn dữ liệu hỗ trợ lẫn nhau. Vừa đa năng vừa chuyên sâu – FlexOlmo đã cho thấy “team chuyên gia” khi kết hợp đúng cách sẽ lợi hại hơn hẳn mỗi người đánh lẻ.
AN TOÀN DỮ LIỆU: NGĂN RÒ RỈ VÀ QUYỀN RIÊNG TƯ
Một câu hỏi nhạy cảm: nếu tôi chia sẻ mô-đun đã huấn luyện trên dữ liệu của mình, liệu người khác có thể tái dựng lại dữ liệu gốc từ mô-đun đó không? Đây là mối lo hoàn toàn chính đáng, nhất là với dữ liệu nhạy cảm. Nhóm nghiên cứu đã chủ động kiểm tra rủi ro này bằng cách thử một đòn tấn công trích xuất dữ liệu trên chính mô-đun expert của FlexOlmo.
Họ huấn luyện một expert về dữ liệu toán học (math) và cố tình “quá luyện” (overfit) nhẹ để tăng khả năng bị lộ. Kết quả thu được khá khả quan: tỷ lệ trích xuất thành công dữ liệu gốc chỉ khoảng 0,7%, cực kỳ thấp. Để so sánh, nếu một mô hình bị nhồi quá đà trên một tập dữ liệu nhỏ (không theo kiến trúc FlexOlmo) thì tỷ lệ lộ dữ liệu có thể lên tới 60% trong thí nghiệm tương tự – tức là cách tấn công này thực sự rất mạnh, nhưng FlexOlmo đã hạn chế rò rỉ tốt hơn nhiều. Những con số này cho thấy việc truy xuất lại một lượng đáng kể dữ liệu huấn luyện từ FlexOlmo là rất khó trong thực tế.
Tuy nhiên, không gì là tuyệt đối an toàn.
Nếu chủ dữ liệu vẫn thấy lo ngay ngáy với dù chỉ 0,7% rủi ro, họ hoàn toàn có thể kết hợp thêm các biện pháp bảo vệ. Một trong những kỹ thuật hàng đầu là áp dụng học máy riêng tư vi phân (Differential Privacy) khi huấn luyện expert – cách này sẽ đảm bảo về mặt toán học rằng dữ liệu gốc không thể bị suy ra ở mức độ cá nhân. Điểm hay là việc áp dụng DP hoàn toàn độc lập với kiến trúc FlexOlmo: mỗi bên dữ liệu tùy nhu cầu tự quyết định có dùng DP hay không cho module của mình mà không ảnh hưởng đến ai.
Tựu trung, FlexOlmo đã tương đối an toàn so với việc chia sẻ dữ liệu thô, và còn cho phép tích hợp thêm “giáp bảo vệ” như DP nếu cần – dữ liệu của bạn được đặt dưới quyền kiểm soát của chính bạn cả về mặt sử dụng lẫn bảo mật.
CÀI ĐẶT VÀ TRẢI NGHIỆM THỬ FLEXOLMO
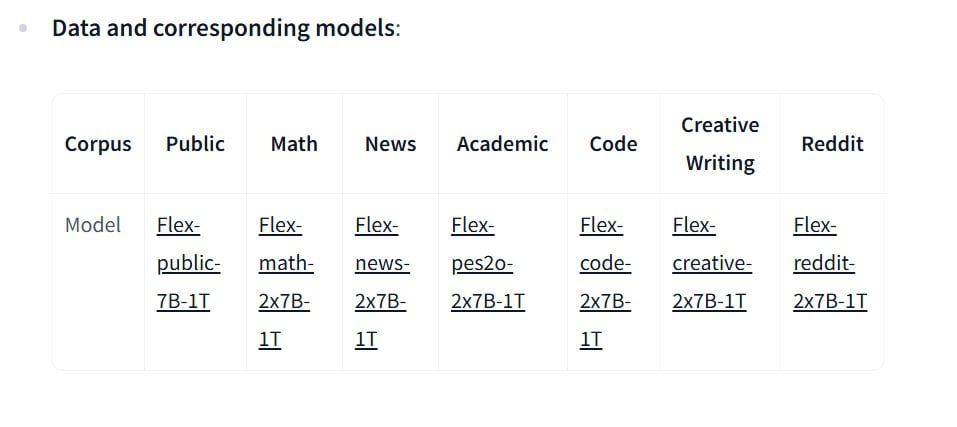
Là một dự án mã nguồn mở, FlexOlmo đã được Ai2 công bố mã code và mô hình mẫu để cộng đồng thử nghiệm. Bạn có thể tìm thấy mã nguồn trên GitHub của AllenAI/FlexOlmo, và thậm chí tải về mô hình đã huấn luyện sẵn (ví dụ FlexOlmo-7x7B-1T, ~33 tỷ tham số) trên HuggingFace để dùng thử. Mô hình mẫu này gồm 7 expert chuyên về các lĩnh vực khác nhau (từ tin tức, toán học cho đến mã lập trình, v.v.), được ghép chung với một mô hình nền 7 tỷ tham số – tổng thể tạo thành một MoE “7 chuyên gia” đầy sức mạnh. Dù 33B tham số vẫn còn khá lớn, việc có sẵn mô hình sẽ hữu ích cho các nhà nghiên cứu muốn đánh giá hoặc fine-tune thêm.
Để các bạn mới bắt đầu có thể hình dung, việc cài đặt FlexOlmo cũng tương tự như nhiều dự án PyTorch khác. Ai2 khuyến nghị dùng Python 3.10 và cài đặt trước PyTorch phù hợp với hệ thống (GPU, CUDA… tùy nhu cầu). Sau đó, ta có thể thực hiện các bước sau để thiết lập môi trường và cài thư viện FlexOlmo:
git clone https://github.com/allenai/FlexOlmo.git
cd FlexOlmo
conda create -n flexolmo python=3.10
conda activate flexolmo
pip install -e “.[train,beaker,wandb]” # Cài đặt các phụ thuộc cho huấn luyện
Các lệnh trên sẽ tải mã nguồn về, tạo một môi trường Python 3.10 (sử dụng conda), kích hoạt môi trường và cài đặt các thư viện cần thiết (bao gồm cả tùy chọn như Beaker, Weights&Biases nếu bạn muốn dùng). Sau đó, bạn đã sẵn sàng để train thử một expert hoặc chạy suy luận với mô hình FlexOlmo. Tài liệu của dự án cũng cung cấp sẵn các script mẫu để huấn luyện cũng như đánh giá mô hình (thư mục src/scripts), giúp bạn táy máy khám phá kết quả của FlexOlmo trên các bộ dữ liệu khác nhau. Nếu không có GPU “khủng” để tự train, bạn vẫn có thể dùng ngay mô hình FlexOlmo đã có sẵn để thử đặt vài câu hỏi và xem nó trả lời ra sao – như một chatbot nhưng với nhiều “não” chuyên gia bên trong.
TƯƠNG LAI AI MỞ VÀ HỢP TÁC

FlexOlmo thực sự mở ra một hướng đi mới cho việc phát triển các mô hình AI lớn. Thay vì mô hình “đóng” nằm trong tay vài gã khổng lồ với dữ liệu thu thập ồ ạt, ta đang hướng tới viễn cảnh các mô hình mở và chung được đồng phát triển bởi nhiều bên dữ liệu khác nhau mà ai cũng hài lòng. Những người sở hữu dữ liệu quý giờ đây có thể tham gia vào hệ sinh thái mô hình ngôn ngữ mở mà không còn e ngại chuyện mất quyền kiểm soát hay phải cam kết “hy sinh” dữ liệu vĩnh viễn. Dữ liệu vẫn là thành phần tối quan trọng để xây dựng AI mạnh mẽ, và FlexOlmo cho thấy một mô hình hợp tác nơi người đóng góp dữ liệu và người phát triển mô hình có thể bắt tay nhau mà không phải đánh đổi những giá trị cốt lõi.
Tất nhiên, FlexOlmo không phải cây đũa thần giải quyết hết mọi vấn đề AI, nhưng nó chứng minh rằng chúng ta có thể vừa “ăn bánh” AI ngon lành, vừa có cách lấy lại “trứng” dữ liệu khi cần. Đó là một bước tiến đầy hứa hẹn để AI trong tương lai trở nên minh bạch, linh hoạt và công bằng hơn cho tất cả các bên. Ai biết đâu, vài năm nữa nhìn lại, chúng ta sẽ thốt lên: “Ồ, thì ra đây mới là cách AI nên được huấn luyện từ đầu!”
- Paper: https://allenai.org/papers/flexolmo
- Code: https://github.com/allenai/FlexOlmo
- Blog: https://allenai.org/blog/flexolmo
- Tải mô hình tại: https://huggingface.co/allenai/FlexOlmo-7x7B-1T